There is a curious trend in machine learning (ML): researchers developing the most capable large language models (LLMs) increasingly evaluate them using manual methods such as red teaming. In red teaming, researchers hire workers to manually try to break the LLM in some form by interacting with it. Similarly, some users (including myself) pick their preferred LLM assistant by manually trying out various models – checking each LLM’s “vibe”. Given that LLM researchers and users both actively seek to automate all sorts of other tasks, red teaming and vibe checks are surprisingly manual evaluation processes. This trend towards manual evaluation hints at fundamental problems that prevent more automatic evaluation methods, such as benchmarks, to be used effectively for LLMs (Ganguli et al., 2023 Ganguli, D., Schiefer, N., Favaro, M. & Clark, J.(2023, 10). Retrieved from https://www.anthropic.com/index/evaluating-ai-systems ; La Malfa et al., 2023 La Malfa, E., Petrov, A., Frieder, S., Weinhuber, C., Burnell, R., Cohn, A., Shadbolt, N. & Wooldridge, M. (2023). The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges. https://doi.org/10.48550/arXiv.2309.16573 ). In this blog post, I aim to give an illustrated overview of the problems preventing LLM benchmarks from being a fully satisfactory alternative to more manual approaches.
Note: This blog post is currently a public draft. Thoughts and feedback are very welcome at contact@arduin.io.
1. Introduction
What’s a benchmark?
An ML benchmark is an automatic evaluation tool that aims to test ML models for a certain model quality. In the context of LLMs, there exist benchmarks for all sorts of model qualities: from ability to translate from French to English (Bojar et al., 2015 Bojar, O., Chatterjee, R., Federmann, C., Haddow, B., Huck, M., Hokamp, C., Koehn, P., Logacheva, V., Monz, C., Negri, M., Post, M., Scarton, C., Specia, L. & Turchi, M. (2015). Findings of the 2015 Workshop on Statistical Machine Translation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 1–46. Retrieved from https://www.research.ed.ac.uk/en/publications/findings-of-the-2015-workshop-on-statistical-machine-translation ) to gender bias of model output (Rudinger et al., 2018 Rudinger, R., Naradowsky, J., Leonard, B. & Van Durme, B. (2018). Gender Bias in Coreference Resolution. https://doi.org/10.48550/arXiv.1804.09301 ). Exactly how a model quality is tested and measured varies widely between benchmarks – I will give a specific example that uses unit tests in the next section. I like to visualise benchmarks as “living” on top of the set of all possible model qualities. Each benchmark is shown as a flag signalling the state of the model quality it is attached to, as illustrated below.
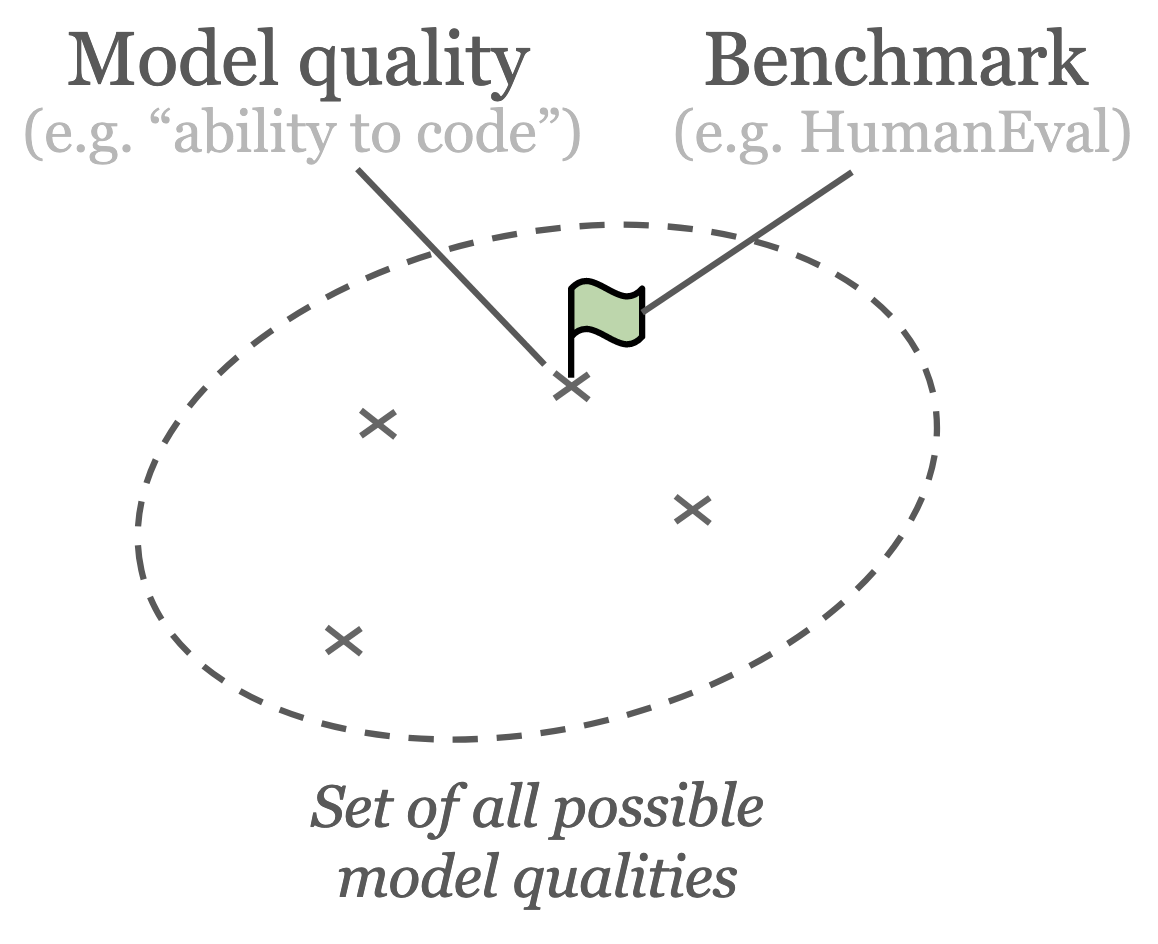
Illustration of a benchmark as a flag providing a signal about the underlying model quality. Each cross represents a model quality. For illustration purposes, only a handful of crosses are shown but there exist infinitely many model qualities.
Benchmarks have been instrumental in guiding machine learning (ML) progress. Whilst inevitably imperfect, benchmarks provide an important signal as to whether one model is “better” than another. This “better” signal enables researchers to decide which ML approach to investigate further – and which to stop investigating. The sharing of benchmark results also enables the synchronisation of ML research: researchers can compare their work to others without having to reproduce their results.
Example benchmark: HumanEval
Throughout this blog post, I will use the HumanEval benchmark (Chen et al., 2021 Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I. & Zaremba, W. (2021). Evaluating Large Language Models Trained on Code. https://doi.org/10.48550/arXiv.2107.03374 ) as an illustrative example. HumanEval aims to evaluate a model’s ability to write Python code by measuring “functional correctness for synthesizing programs from docstrings” (as the authors put it). To test the model quality, the benchmark runs 164 test cases on a model. Each test case consists of a hand-written beginning of a Python function (a function signature and docstring) and corresponding automatic code tests (unit tests). The LLM is tasked to complete the Python function based on just the beginning. The complete Python function, consisting of the pre-written beginning and the LLM’s completion, is then automatically checked using the corresponding code tests. This procedure is repeated for all 164 test cases to obtain the overall number of functions the LLM is able to successfully complete. As far as I understand, the benchmark is called HumanEval, because all its test cases were hand-written by a human – unlike other benchmarks that scrape websites like GitHub.

Example task from HumanEval. The model is tasked to complete the Python function shown.
Disclaimer: Whilst I use HumanEval to demonstrate problems with current benchmarks, HumanEval is a great contribution and generally no worse than most other benchmarks. I picked HumanEval because it’s a well-known and straightforward benchmark.
Manual evaluation of LLMs
In ML research, it’s good practice to not just blindly rely on benchmarks (like HumanEval). Manual evaluation of model outputs is crucial to find failure cases overlooked by benchmarks. However, for LLMs, manual evaluation in the form of red teaming appears to have gained unusually high importance relative to automatic benchmarks. Instead of being the typically small sanity check as in other ML areas, manual evaluation has seemingly become an integral part of evaluating LLMs for many labs. There exist entire leaderboards (such as Chatbot Arena (Zheng et al., 2023 Zheng, L., Chiang, W., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J. & Stoica, I. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. https://doi.org/10.48550/arXiv.2306.05685 )) based on human judgement. Research labs developing the largest models all appear to invest heavily into manual evaluation via red teaming. Exact numbers are difficult to obtain due the secrecy of many commercial labs, but blog posts and public reporting indicate that the investement is sizable (Microsoft, 2023 Microsoft(2023, 11/6). Retrieved from https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/red-teaming ; Ganguli et al., 2023 Ganguli, D., Schiefer, N., Favaro, M. & Clark, J.(2023, 10). Retrieved from https://www.anthropic.com/index/evaluating-ai-systems ; Ganguli et al., 2022 Ganguli, D., Lovitt, L., Kernion, J., Askell, A., Bai, Y., Kadavath, S., Mann, B., Perez, E., Schiefer, N., Ndousse, K., Jones, A., Bowman, S., Chen, A., Conerly, T., DasSarma, N., Drain, D., Elhage, N., El-Showk, S., Fort, S., Hatfield-Dodds, Z., Henighan, T., Hernandez, D., Hume, T., Jacobson, J., Johnston, S., Kravec, S., Olsson, C., Ringer, S., Tran-Johnson, E., Amodei, D., Brown, T., Joseph, N., McCandlish, S., Olah, C., Kaplan, J. & Clark, J. (2022). Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned. https://doi.org/10.48550/arXiv.2209.07858 ; OpenAI, 2023 OpenAI(2023, 9/19). Retrieved from https://openai.com/blog/red-teaming-network ).
Limitations of manual evaluation
There is nothing wrong with doing extensive manual evaluations. On the contrary, it may be considered desirable for more humans to examine and verify model outputs – as opposed to models being shipped blindly relying on benchmark scores. However, just relying on manual evaluation without appropriate automatic evaluation capabilities is problematic: manual evaluation does not scale well. Firstly, extending testing to more models, model qualities, or application areas also requires more workers – making this form of scaling very costly. It may also be difficult due to limited availability of suitable experts. Secondly, there is a ceiling as to what complexity of capabilities humans can evaluate. A human worker will likely struggle to evaluate any superhuman capabilities. Thus, it is easy to conceive overreliance on manual evaluation leading to a poor understanding of increasingly capable models with diverse use-cases. Scalable oversight is a very active research area aiming to investigate and address these problems (Amodei et al., 2016 Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. & Mané, D. (2016). Concrete Problems in AI Safety. https://doi.org/10.48550/arXiv.1606.06565 ).
Given these limitations, it is crucial to identify and address the problems of automatic benchmarks – in order to augment manual evaluation with scalable automatic evaluation. As a step towards solving them, this blog post will run through what I consider to be the main problems that exist with current benchmarks.
2. Problems with individual benchmarks
Problem 1: overfitted benchmarks
Often LMs are overfitted to popular benchmarks. There are two main reasons why a model may be overfitted to a specific benchmark: (1) training data contamination (Yang et al., 2023 Yang, S., Chiang, W., Zheng, L., Gonzalez, J. & Stoica, I. (2023). Rethinking Benchmark and Contamination for Language Models with Rephrased Samples. https://doi.org/10.48550/arXiv.2311.04850 ) or (2) usage for hyperparameter tuning (Goodhart’s Law). In the first case, the benchmark’s data ends up in the model’s training data. Thus, the model may perform well on the benchmark by memorizing the correct solution, but not generalize equally well beyond the test cases. Any benchmark measurement will be distorted and mostly useless (unless you want to measure memorization). When a benchmark is used for model hyperparameter tuning, a slightly more indirect form of overfitting occurs: the benchmark data itself is not leaked but information about the data. Thus, Goodhart’s Law applies and the benchmark’s results similarly become less meaningful.
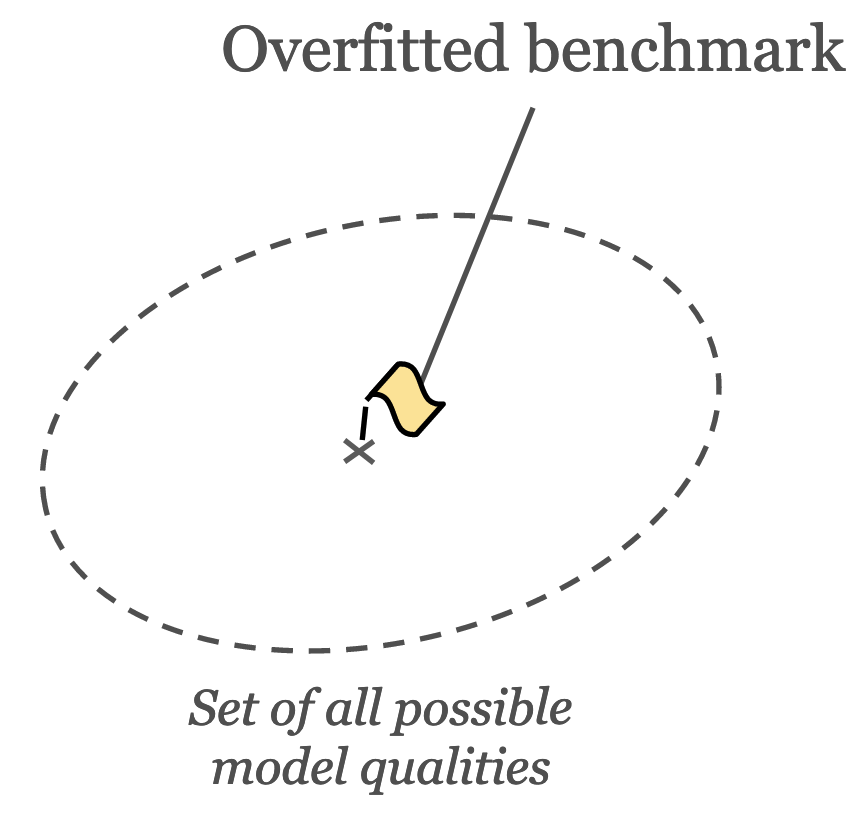
Illustration of a benchmark that models are overfitted to.
Problem 2: saturated benchmarks
Usually benchmarks become saturated over time and are no longer able to effectively separate top models. When created initially, benchmarks are usually at the edge of what is possible with current models. They usually test a model quality which top models exhibit to a varying degree, and none fully exhibit. Over time, as models become more capable, the top models increasingly perform better and better on the benchmark. Eventually, there remains very little, or even no test cases, that separate different models. For example, HumanEval may be considered as quite saturated.
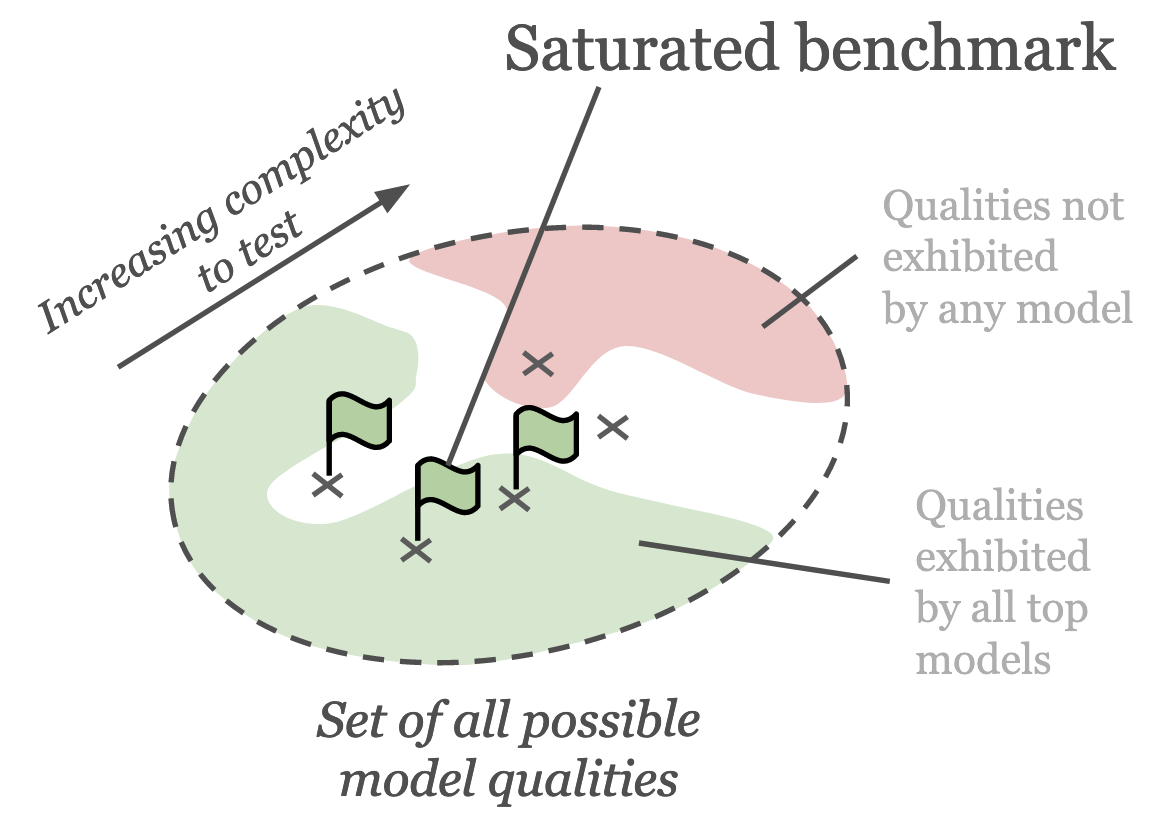
Illustration of a saturated benchmark that no longer is able to distinguish between top models.
Problem 3: misunderstood benchmarks
Users often do not fully understand what model quality a benchmark actually evaluates. Whilst benchmarks are often built with a general model quality in mind, practical limitations mean that benchmark tasks are usually focused on a much narrower subquality. For example, HumanEval is often seen as a test for Python coding ability, yet the benchmark itself only focuses on writing individual Python functions based on docstrings. The benchmark does not cover anything like classes or more complex code structure. Additionally, as benchmarks become more saturated (i.e. best models solve most tasks), the top models get separated by a vanishingly small subset of tasks. Thus, a saturated benchmark often tests a narrower model quality than the initial quality of the benchmark. For example, in HumanEval the difference between top models like GPT-4 and Claude-2 primarily centers around a small set of problems, often with slightly ambiguous framing. In other cases, benchmarks are claimed to be more general than they actually are, leading to a misunderstanding. In practice, misunderstood benchmarks are counterproductive for decision making and can lead to reduced trust in benchmarks.
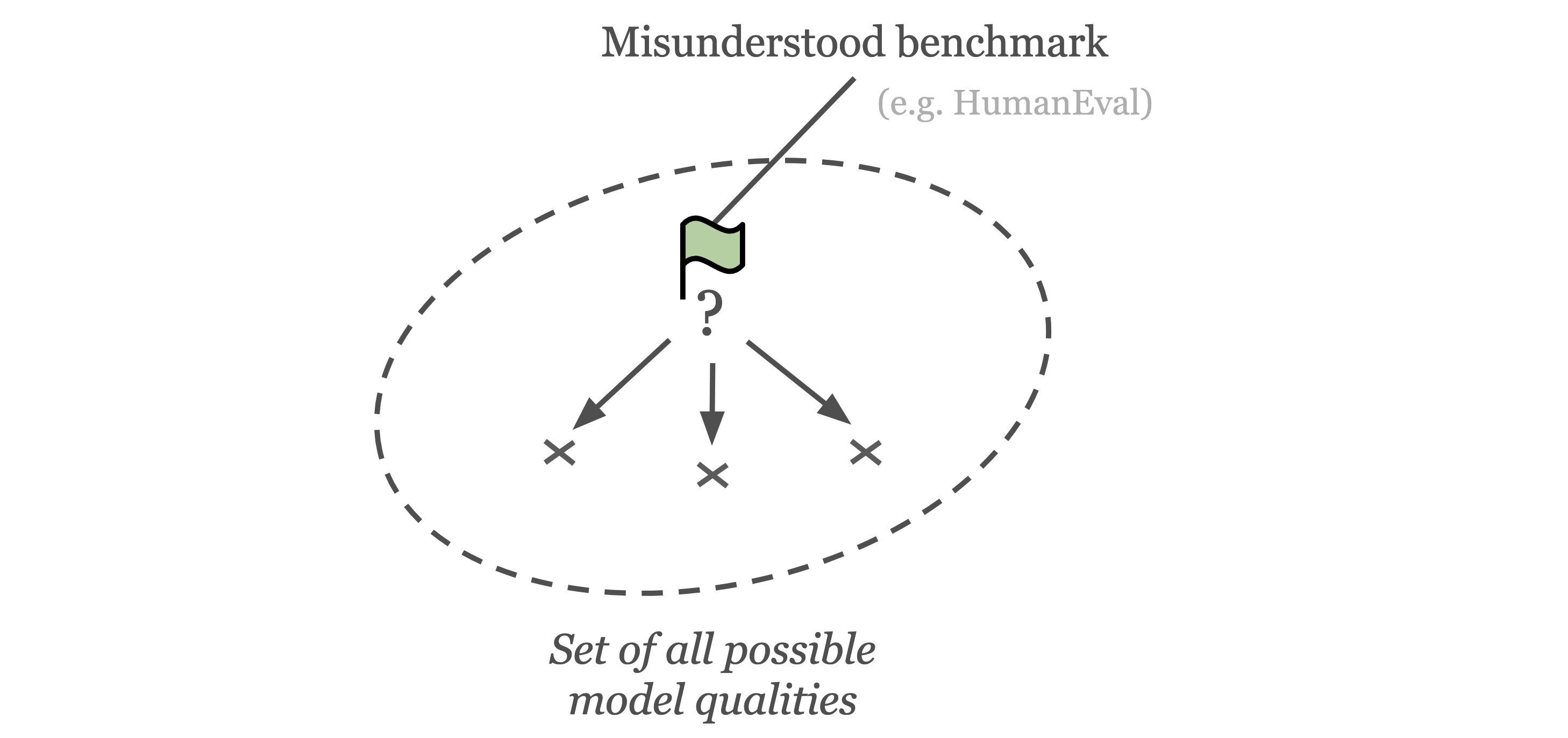
Illustration of users misunderstanding the model quality evaluated by a benchmark. For example, whilst people widely understand the HumanEval benchmark to evaluate "coding ability", the model quality evaluated by the benchmark may be more accurately described as "ability to correctly complete Python functions".
Problem 4: expensive benchmarks
Some benchmarks require significant effort to run them. There are two main reasons: (1) setup cost and (2) compute cost. The first is about how much effort it is to run the benchmark. Some popular benchmarks such as BBQ (Parrish et al., 2021 Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P. & Bowman, S. (2021). BBQ: A hand-built bias benchmark for question answering. arXiv preprint arXiv:2110.08193. Retrieved from https://arxiv.org/abs/2110.08193 ) can be work intensive to get up and running. There are reports of the setup of BBQ requiring a software engineer a full work week (Ganguli et al., 2023 Ganguli, D., Schiefer, N., Favaro, M. & Clark, J.(2023, 10). Retrieved from https://www.anthropic.com/index/evaluating-ai-systems ). This prevents more resource-strapped users from running these benchmarks in the first place. Similarly, many benchmarks require a large amount of compute for model inference to use them. If you didn’t trust the reported results and wanted to test your OpenAI API on the standard HELM benchmark (Liang et al., 2022 Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C., Ré, C., Acosta-Navas, D., Hudson, D., Zelikman, E., Durmus, E., Ladhak, F., Rong, F., Ren, H., Yao, H., Wang, J., Santhanam, K., Orr, L., Zheng, L., Yuksekgonul, M., Suzgun, M., Kim, N., Guha, N., Chatterji, N., Khattab, O., Henderson, P., Huang, Q., Chi, R., Xie, S., Santurkar, S., Ganguli, S., Hashimoto, T., Icard, T., Zhang, T., Chaudhary, V., Wang, W., Li, X., Mai, Y., Zhang, Y. & Koreeda, Y. (2022). Holistic Evaluation of Language Models. https://doi.org/10.48550/arXiv.2211.09110 ), you may have to spend a lot of money (HELM lite is an interesting alternative).
illustration of how some benchmarks are expensive to run.
3. Problems with benchmark ecosystem
Problem 5: missing benchmarks
For many model qualities, benchmarks could be created but haven’t been created yet. There are an infinite number of possible model qualities to evaluate. For any given benchmark, it is easy to construct an adjacent model quality that is not yet measured by a benchmark. For example, whilst HumanEval aims to evaluate “ability to write Python code”, we may instead care about “ability to write Python code using framework X”. As benchmarks are typically handcrafted, most LM qualities do not have a corresponding existing benchmark – a benchmark for those qualities is missing. For multi-use systems like LLMs, developers are frequently exploring new use-cases with no corresponding benchmarks. The figure below illustrates how most model qualities do not have a corresponding benchmark.
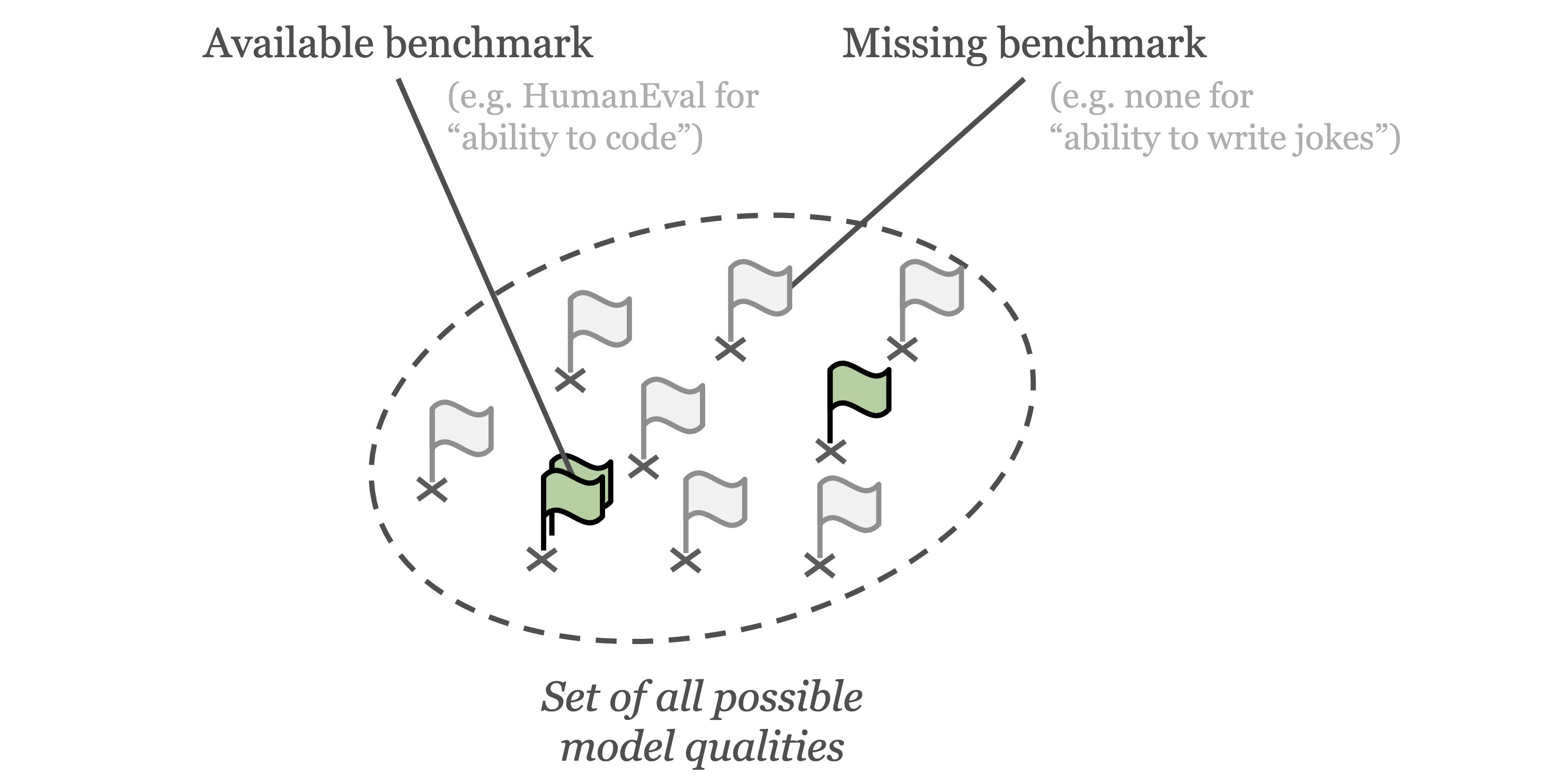
Illustration of how for many model qualities the corresponding benchmarks are missing.
Problem 6: unfeasible benchmarks
Some model qualities are too difficult to measure with current methods. Whilst HumanEval evaluates writing short Python functions, the job of a software engineer involves many other tasks, including creating pull-requests, co-ordinating with a team, or coming up with a good system architecture. Due to the complexity of testing some of these tasks, no benchmark exists that captures all model qualities required for an LM to take over an software engineering role. The field of scalable oversight (Amodei et al., 2016 Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. & Mané, D. (2016). Concrete Problems in AI Safety. https://doi.org/10.48550/arXiv.1606.06565 ) aims to tackle the problem of evaluating increasingly complex model qualities, especially when models exhibit qualities that surpass human capabilities.
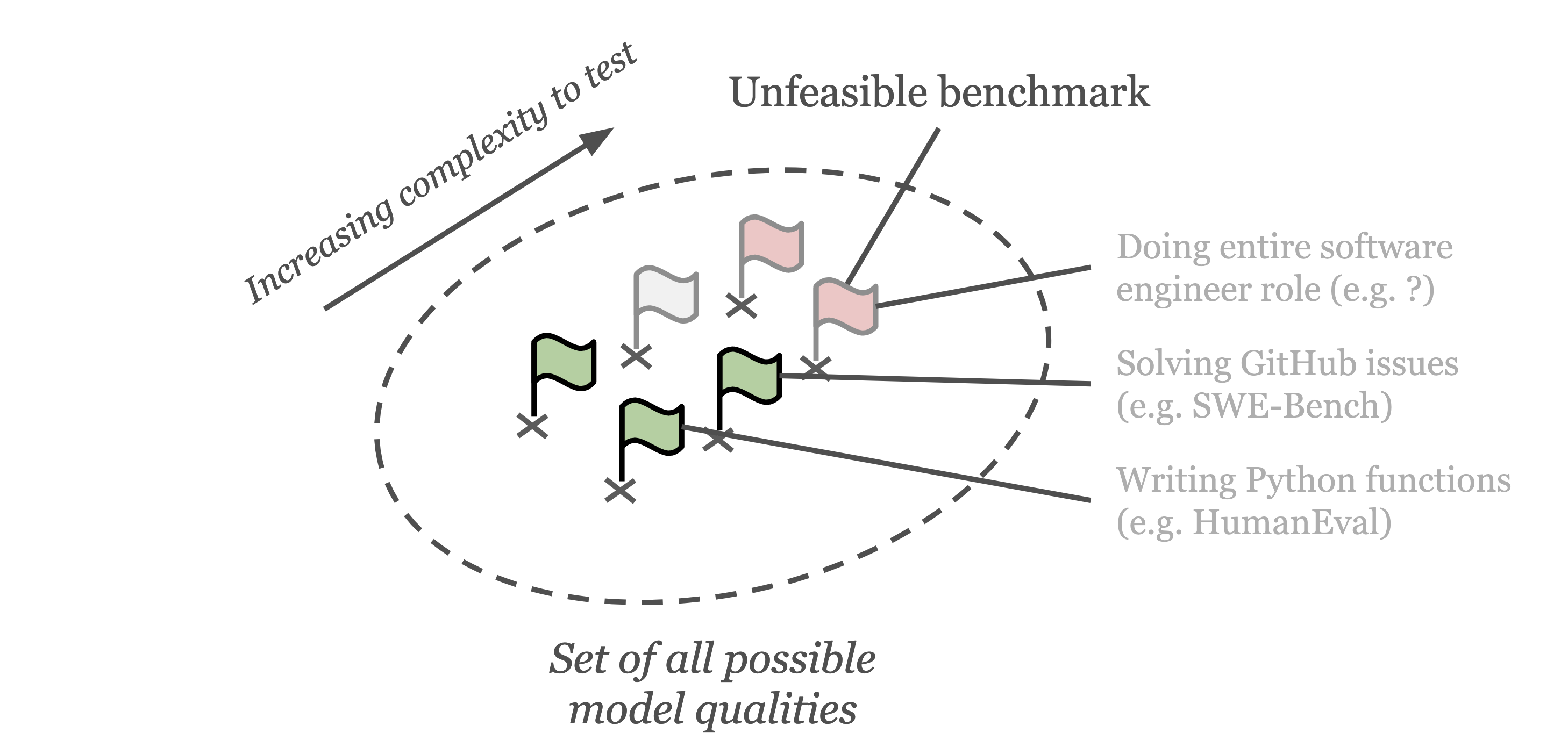
Illustration of how many model qualities are too complex to evaluate with current benchmark methods.
Problem 7: aimless benchmarks
Some users do not know what qualities they want their LM to have. Unlike previous ML systems, LMs have become truly multi-use. The same model may be used as a writing assistant, translator, therapist, or code autocomplete engine. Due to the open-ended nature of model uses, model developers struggle to explicitly state what model qualities they aim for. Qualities tend to be very ambiguous, such as harmless and helpful. Without clarity around desirable model qualities, it is impossible to identify or create a suitable benchmark. Model developers rely heavily on red teaming as opposed to automatic benchmarks – as this more closely aligns with model use. I believe the reason why traditional benchmarks are not held in high regard by model developers is primarily because they require the developers to decide what’s important – what qualities to test. This issue was well summarized in this podcast (Bashir & Benaich, 2023 Bashir, D. & Benaich, N. (2023). 2023 in AI with Nathan Benaich. Retrieved from https://open.spotify.com/episode/5CV9ongsBGbjtF5SgfgDNF?si=cDhbu8KET5OIB7XdsfXI6w&t=1138 ). Red teaming allows model developers to implicitly let the red team members decide what model qualities to test, instead of the developers having to state them explicitly.
Illustration of how some benchmark users aimlessly (almost randomly) select benchmarks and model qualities to evaluate. This issue often arises due to a lack of clarity around what qualities matter for their LM application.
4. Conclusion
Whilst my list of problems above certainly is incomplete, I hope it helped provide some clarity around what some of the most important issues of benchmarks are. I believe that it is vital to be aware of these problems whenever using – and especially when developing – benchmarks. Each problem also presents an interesting research direction for future work.
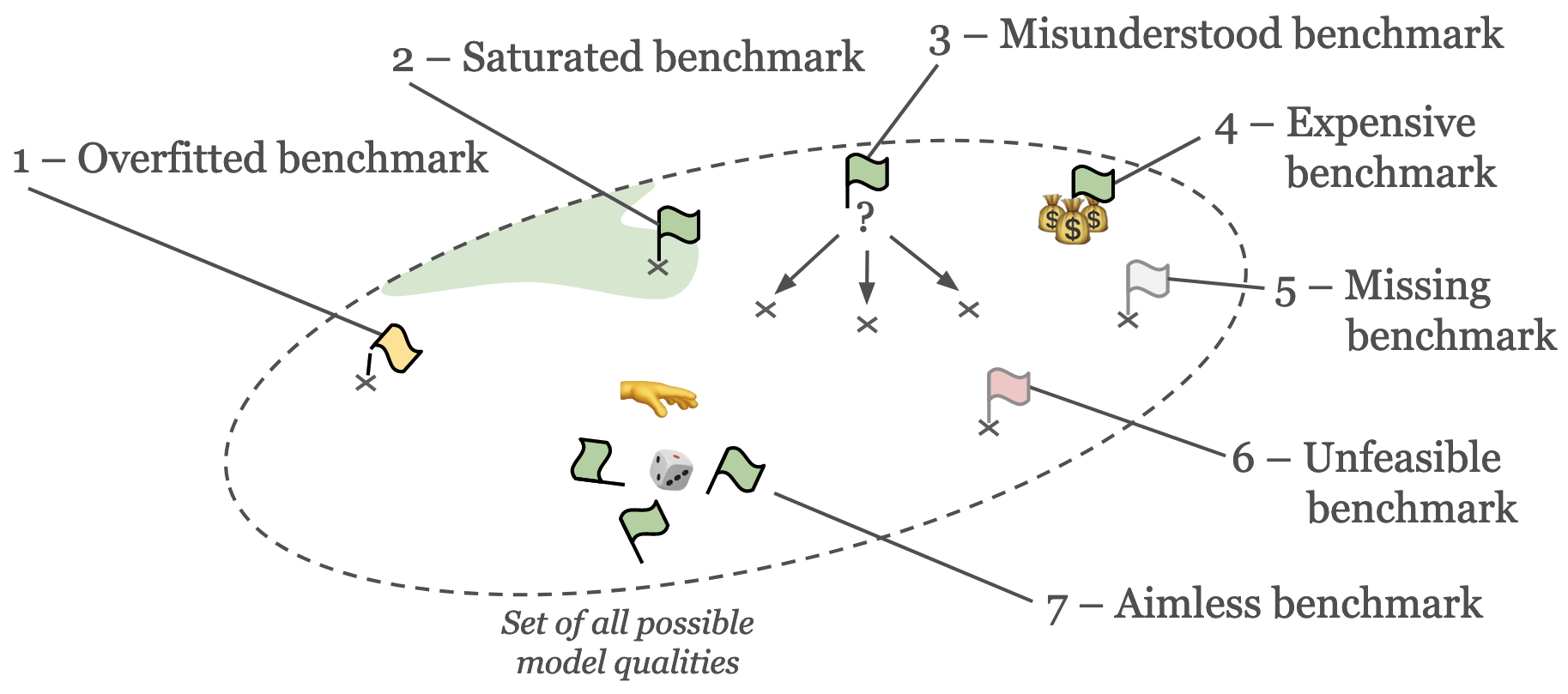
Overview of all problems discussed.
Want to read further? I can recommend Anthropic’s blog post on the topic (Ganguli et al., 2023 Ganguli, D., Schiefer, N., Favaro, M. & Clark, J.(2023, 10). Retrieved from https://www.anthropic.com/index/evaluating-ai-systems ). If you’re looking for a more comprehensive overview over all benchmarks, consider looking at a survey over language model evaluation (e.g. Chang et al. (2023 Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P., Yang, Q. & Xie, X. (2023). A Survey on Evaluation of Large Language Models. https://doi.org/10.48550/arXiv.2307.03109 ; Guo et al. (2023 Guo, Z., Jin, R., Liu, C., Huang, Y., Shi, D., Supryadi, Yu, L., Liu, Y., Li, J., Xiong, B. & Xiong, D. (2023). Evaluating Large Language Models: A Comprehensive Survey. https://doi.org/10.48550/arXiv.2310.19736 ).)
Acknowledgements
Big thanks to the many people I have been extensively discussing benchmarks with, especially Samuel Albanie, Rob Mullins and Benjamin Minixhofer. I would also like to highlight the useful discussions I had at the Evaluating Foundation/Frontier Models Workshop organised by Emanuele La Malfa et al. – this helped clarify my thoughts.
Versions
- v1 (2024-01-15): initial public draft release
References
- Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. & Mané, D. (2016). Concrete Problems in AI Safety. https://doi.org/10.48550/arXiv.1606.06565
- Bashir, D. & Benaich, N. (2023). 2023 in AI with Nathan Benaich. Retrieved from https://open.spotify.com/episode/5CV9ongsBGbjtF5SgfgDNF?si=cDhbu8KET5OIB7XdsfXI6w&t=1138
- Bojar, O., Chatterjee, R., Federmann, C., Haddow, B., Huck, M., Hokamp, C., Koehn, P., Logacheva, V., Monz, C., Negri, M., Post, M., Scarton, C., Specia, L. & Turchi, M. (2015). Findings of the 2015 Workshop on Statistical Machine Translation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 1–46. Retrieved from https://www.research.ed.ac.uk/en/publications/findings-of-the-2015-workshop-on-statistical-machine-translation
- Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P., Yang, Q. & Xie, X. (2023). A Survey on Evaluation of Large Language Models. https://doi.org/10.48550/arXiv.2307.03109
- Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I. & Zaremba, W. (2021). Evaluating Large Language Models Trained on Code. https://doi.org/10.48550/arXiv.2107.03374
- Ganguli, D., Lovitt, L., Kernion, J., Askell, A., Bai, Y., Kadavath, S., Mann, B., Perez, E., Schiefer, N., Ndousse, K., Jones, A., Bowman, S., Chen, A., Conerly, T., DasSarma, N., Drain, D., Elhage, N., El-Showk, S., Fort, S., Hatfield-Dodds, Z., Henighan, T., Hernandez, D., Hume, T., Jacobson, J., Johnston, S., Kravec, S., Olsson, C., Ringer, S., Tran-Johnson, E., Amodei, D., Brown, T., Joseph, N., McCandlish, S., Olah, C., Kaplan, J. & Clark, J. (2022). Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned. https://doi.org/10.48550/arXiv.2209.07858
- Ganguli, D., Schiefer, N., Favaro, M. & Clark, J.(2023, 10). Retrieved from https://www.anthropic.com/index/evaluating-ai-systems
- Guo, Z., Jin, R., Liu, C., Huang, Y., Shi, D., Supryadi, Yu, L., Liu, Y., Li, J., Xiong, B. & Xiong, D. (2023). Evaluating Large Language Models: A Comprehensive Survey. https://doi.org/10.48550/arXiv.2310.19736
- La Malfa, E., Petrov, A., Frieder, S., Weinhuber, C., Burnell, R., Cohn, A., Shadbolt, N. & Wooldridge, M. (2023). The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges. https://doi.org/10.48550/arXiv.2309.16573
- Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C., Ré, C., Acosta-Navas, D., Hudson, D., Zelikman, E., Durmus, E., Ladhak, F., Rong, F., Ren, H., Yao, H., Wang, J., Santhanam, K., Orr, L., Zheng, L., Yuksekgonul, M., Suzgun, M., Kim, N., Guha, N., Chatterji, N., Khattab, O., Henderson, P., Huang, Q., Chi, R., Xie, S., Santurkar, S., Ganguli, S., Hashimoto, T., Icard, T., Zhang, T., Chaudhary, V., Wang, W., Li, X., Mai, Y., Zhang, Y. & Koreeda, Y. (2022). Holistic Evaluation of Language Models. https://doi.org/10.48550/arXiv.2211.09110
- Microsoft(2023, 11/6). Retrieved from https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/red-teaming
- OpenAI(2023, 9/19). Retrieved from https://openai.com/blog/red-teaming-network
- Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P. & Bowman, S. (2021). BBQ: A hand-built bias benchmark for question answering. arXiv preprint arXiv:2110.08193. Retrieved from https://arxiv.org/abs/2110.08193
- Rudinger, R., Naradowsky, J., Leonard, B. & Van Durme, B. (2018). Gender Bias in Coreference Resolution. https://doi.org/10.48550/arXiv.1804.09301
- Yang, S., Chiang, W., Zheng, L., Gonzalez, J. & Stoica, I. (2023). Rethinking Benchmark and Contamination for Language Models with Rephrased Samples. https://doi.org/10.48550/arXiv.2311.04850
- Zheng, L., Chiang, W., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J. & Stoica, I. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. https://doi.org/10.48550/arXiv.2306.05685
Appendix
A. Additional problems
The previous list is not necessarily exhaustive. Some problems related to benchmarks are not about benchmarks themselves, but the systems we are trying to evaluate. Other problems may be considered sub-problems of one of the mentioned problems.
- Model stochasticity: difficult to reproduce when using models via LLM-as-a-Service
- Brittle benchmarks that can be easily fooled and are not robust to minor prompt pertubations. May be covered by misunderstood and overfitted cases.
- (Red teaming lacks standardisation: not about benchmarks, but a common complaint in the community)
Citation
If you found this post useful for your work, please consider citing it as:
orFindeis, Arduin. (Jan 2024). The benchmark problems reviving manual evaluation. Retrieved from https://arduin.io/blog/benchmark-problems/.
@article{Findeis2023Thebenchmarkproblemsrevivingmanualevaluation,
title = "The benchmark problems reviving manual evaluation",
author = "Findeis, Arduin",
journal = "arduin.io",
year = "2024",
month = "January",
url = "https://arduin.io/blog/benchmark-problems/"
}